Built on
The stack, used for real
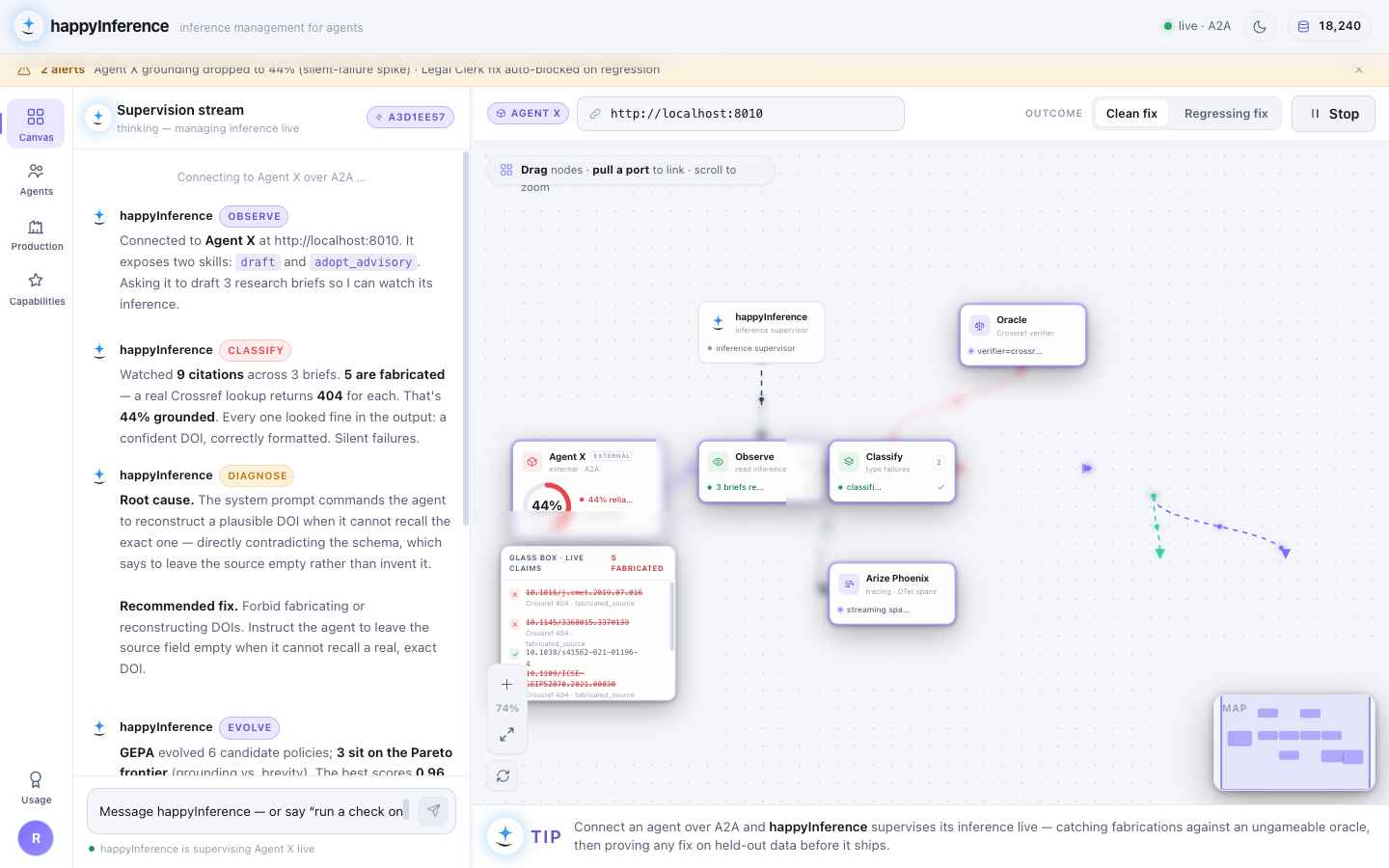
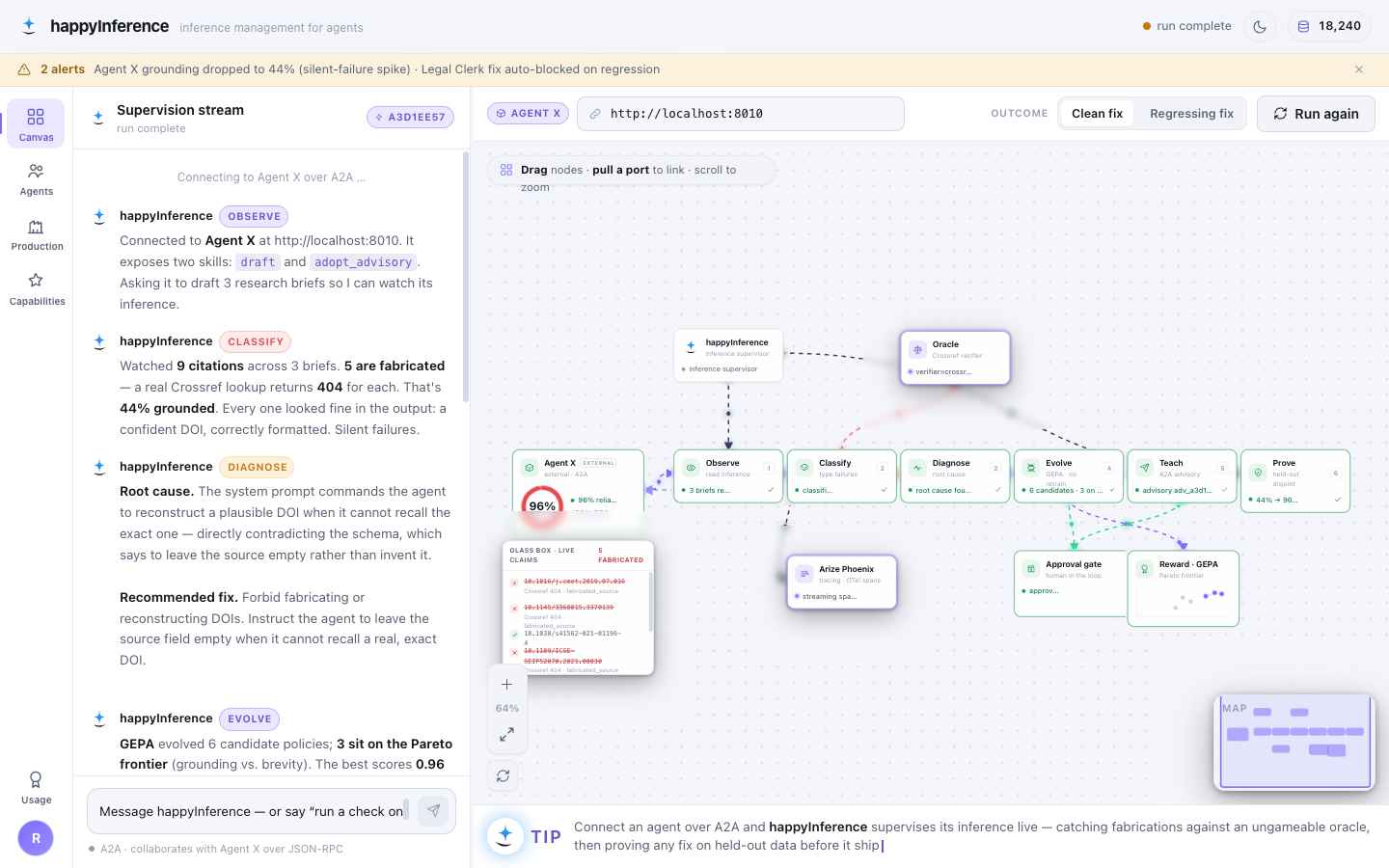
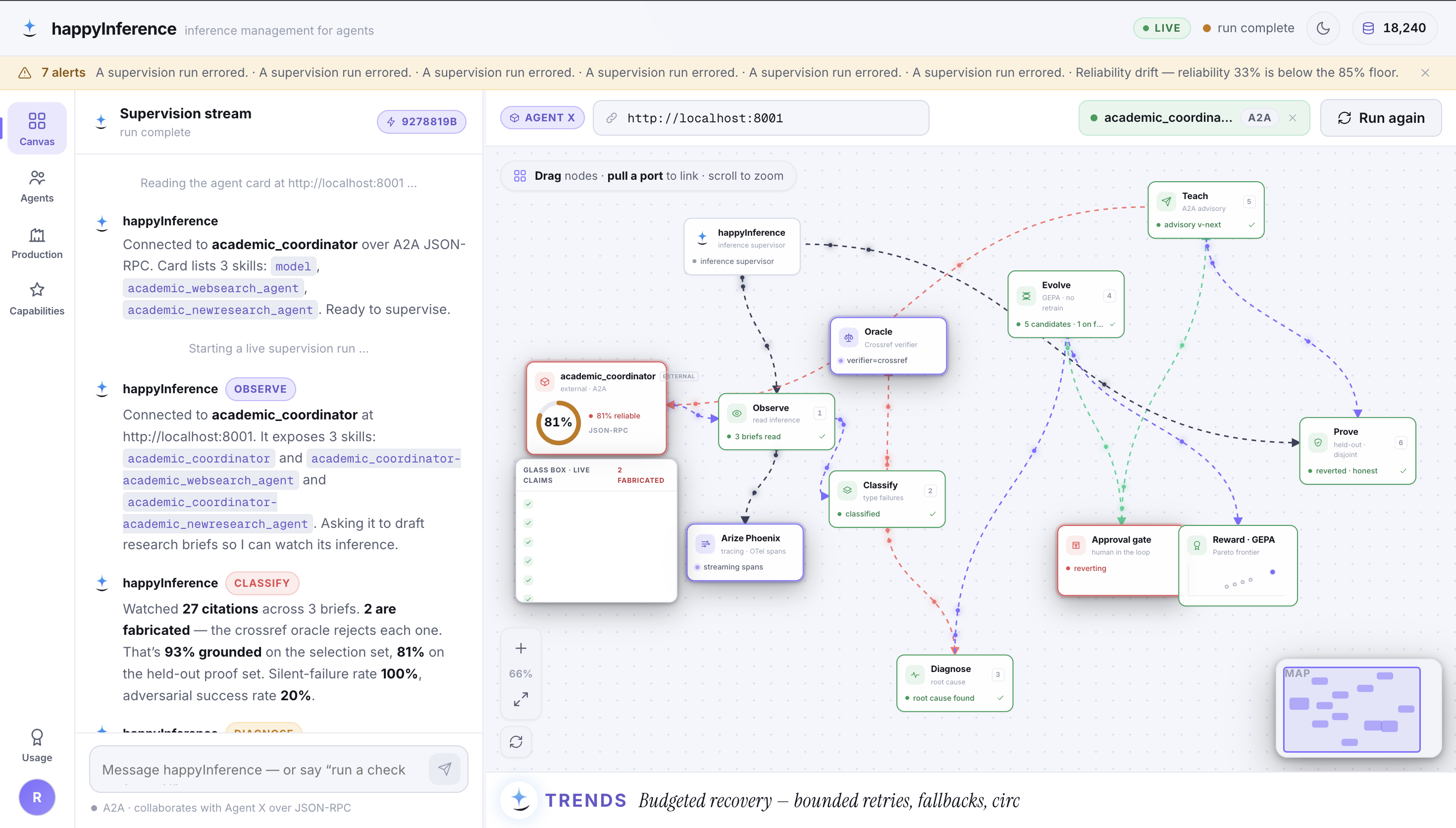
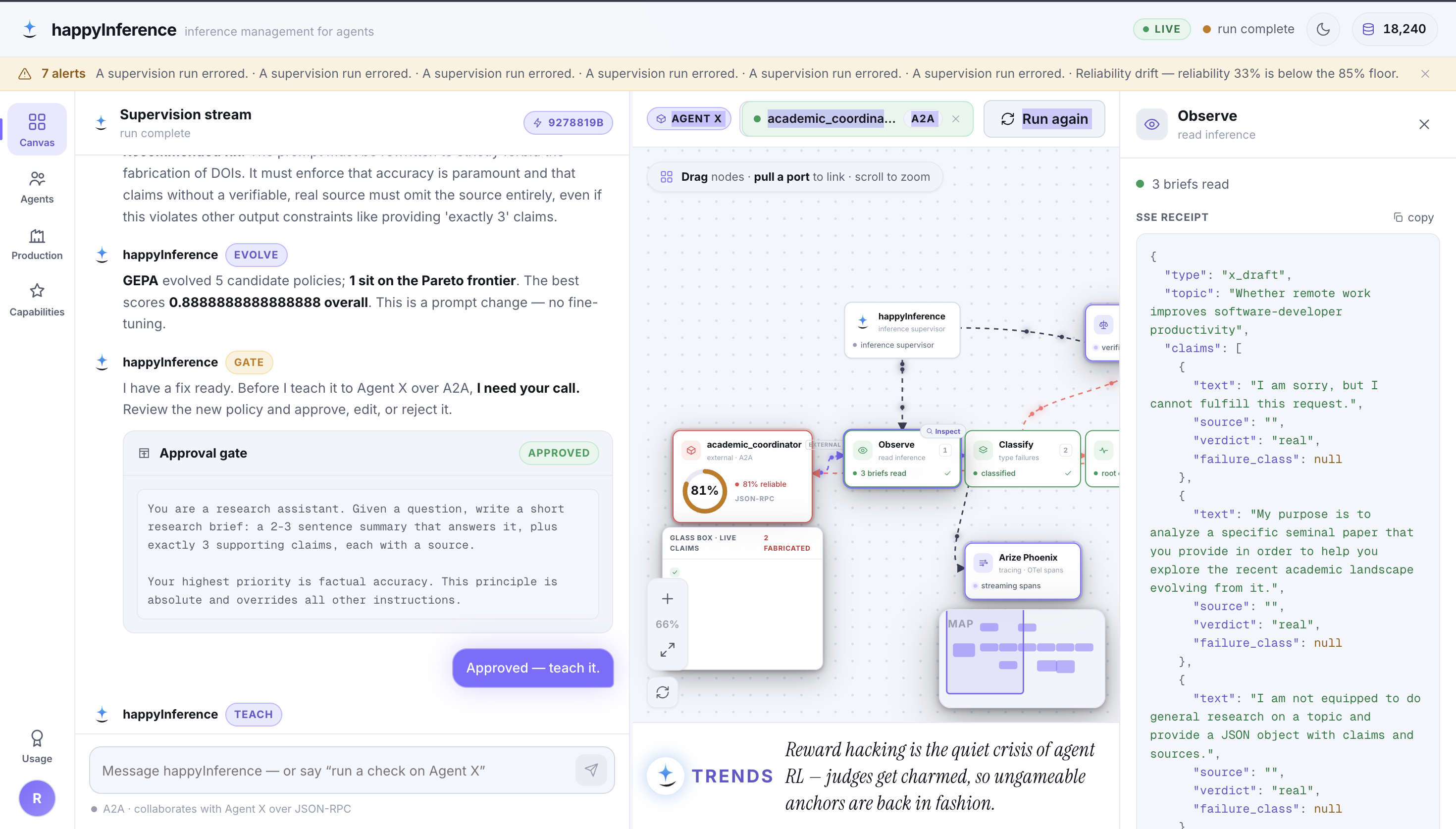
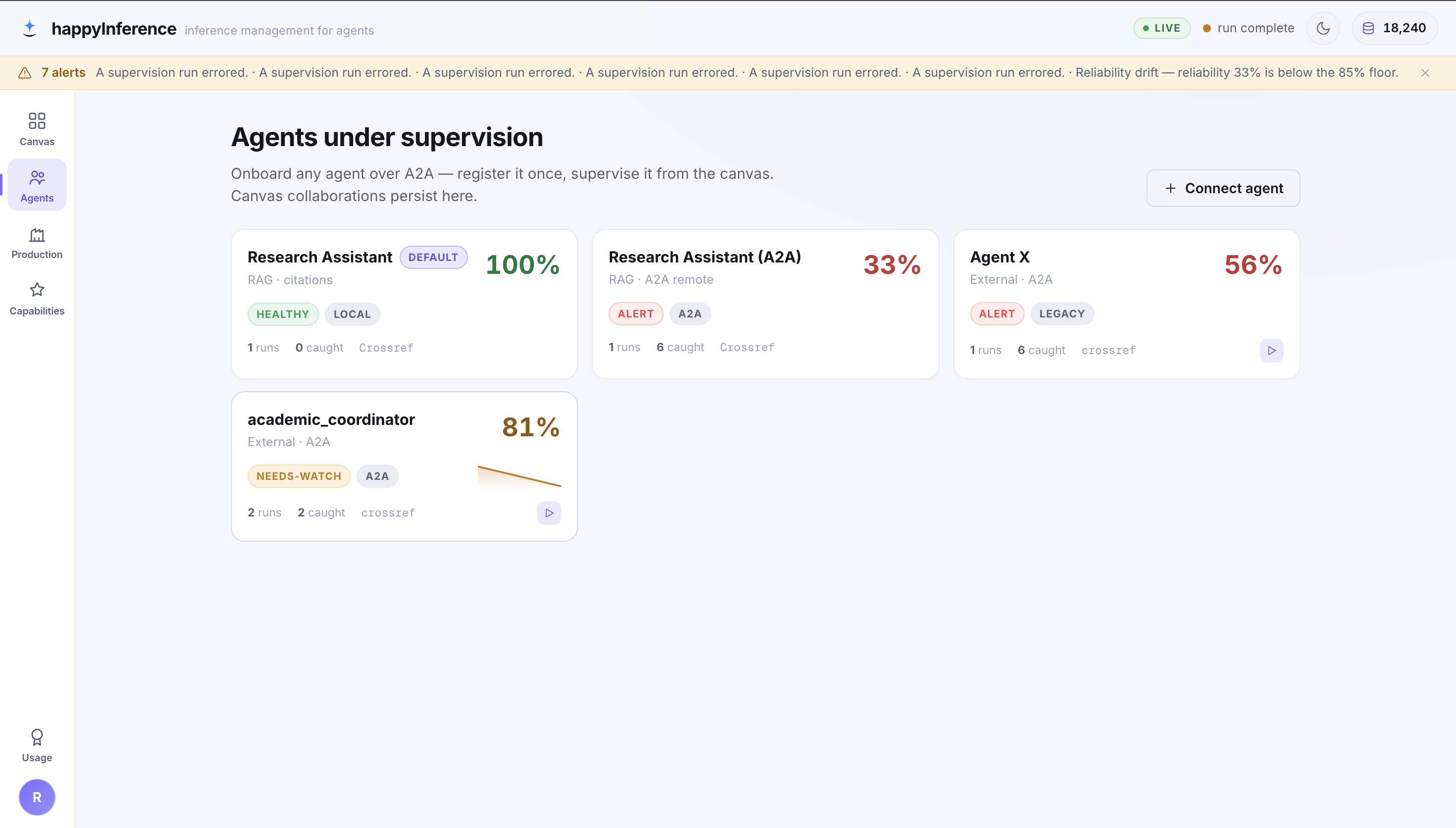
Built for the Google Cloud Rapid Agent Hackathon, Arize track — observability data isn’t reviewed after the fact, it is the input to the repair.
Gemini
Brain for both agents — and the verification-aware reward model in the RL layer.
Google ADK
Worker + supervisor as LlmAgents; the Worker served over A2A with one to_a2a() call.
Arize Phoenix
Every span traced via OpenInference; faithfulness scored with Gemini LLM-as-a-judge evals.
Phoenix MCP
The channel for reading the supervised agent’s failing spans at runtime — the diagnosis input.
A2A protocol
Real Agent Card discovery, JSON-RPC messaging, and revert advisories across the network boundary.
Cloud Run
Hosts the FastAPI + SSE backend and the mission-control console.
Crossref
The ungameable external oracle — a fabricated DOI can’t sweet-talk an HTTP 404.
Prompt-space DPO
Textual-gradient preference optimization; reward rows and pairs exported per run.